AI,인공지능에 대한 오해 (2부: 챗GPT비평) feat. 노암 촘스키, 개리 마커스
앞서 AI,인공지능에 대한 오해 (1부: Science Fiction과 Fact 구분하기)에서는 AI/인공지능이란 개념 이해 부족과 대중매체를 통해 익숙해진 공상과학 속의 AGI(Artificial General Intelligence)를 구분하는데 초점을 두었습니다.
게시물 용량의 한계 때문인지 더 이상 내용추가가 되지 않아 부득이하게 2부로 넘어왔습니다.
2부에서는 아래 순서대로 진행해보려 합니다.
(1) ChatGPT에 대한 Deep한 Learning/알아보는 시간 (계속)
(2) Open AI사의 서비스인 ChatGPT, Dall.E 등의 인공지능에 대한 비평
* (1)과 (2)를 섞어서 진행해보려 합니다.
(3) AI/인공지능에 대한 환상의 근원
Open AI사의 샘 알트만(Sam Altman)은 Lex Fridman과의 팟캐스트에서 이렇게 말했습니다.
제 생각엔 대중에게 이게 '피조물/생명체(creature)'가 아니라 도구라는 걸 설명하고 교육하는 게 아주 중요한 것 같습니다.
I think it's really important to explain, we tried to, we explain, educate people that this is a tool, not a creature.
-OPEN AI사의 샘 알트만(Sam Altman) -
2. WebSummit 2023에서의 Gary Marcus 와 Noam Chomsky의 비평
프로그램 제목: Debunking the great AI lie (직역: AI에 대한 거대한 거짓말을 까발리다)
인터뷰어: 제레미 칸 (Jeremy Kahn 포츈 매거진 소속)
인터뷰대상: 개리 마커스(Gary Marcus/ 뉴욕대학교 명예교수, Robust.AI 창립자), 노암 촘스키 (Noam Chomsky/ 언어학자, 인지과학자)

제레미 칸(Jeremy Kahn):
많은 사람들이 우리가 인공지능의 황금기를 거치고 있다고 생각하죠.
달리(Dall.E)나 스테이블 디퓨전(Stable Diffusion)과 같은 텍스트 입력으로 이미지를 생성할 수 있는 인공지능시스템과 관련해서 많은 광풍(狂风)/열풍/과대선전이 넘치고 있습니다. 한편 인간의 텍스트 입력으로 일관성 있는 텍스트를 생성해낼 수 있는 Open AI사의 GPT-3에 대해서도 많은 대화가 이뤄지고 있습니다. 많은 사람들이 이 기술의 흐름에 대해 흥분하고 있는데, 선생님(노암 촘스키)께서는 그렇지 않다고 알고 있습니다. 도리어 이 기술의 현위치에 대해 실망하고 있다고 하셨다고요.
왜 그런가요?
노암 촘스키(Noam Chomsky):
(송출문제로 초반에 음성이 전달되지 않음).

어떤 시스템은 충분히 강력하지 못해서 문제가 되죠.
특정 업무를 처리해내지 못하는 경우가 그렇죠.
반면에 한 시스템이 너무 강할 경우에 이 문제는 고칠 수 없습니다.
보편적으로.
GPT와 유사한 다른 시스템들의 문제점이 바로 그러죠.
만약 언어의 규칙들을 위반하는 "언어가 아닌 텍스트(impossible language)"로 구성된 데이터베이스를 챗GPT에 줘도 별 문제 없이 작동할 겁니다. 규칙이 더 간단해졌으니깐요.
예를 들면 언어가 작용하는 기초적인/근본적인 특성 중 하나는 언어의 선형적 순서를 무시하지 말아야 된다는 거죠. (하지만) 이 시스템들은 모든 걸 무시하고 추상적 구조에만 집중하죠.
(중략)
문제는 그건 언어가 아니라는 거죠. 하지만 GPT는 개의치 않습니다.
예를 만들어보자면, 만약에 누군가가 "새로운 원소주기표"에 존재 가능한(존재하고 있는 원소)와 존재하지 않는(존재할 수 없는) 원소를 나란히 나열해서 두 종류에 대해 구분을 하지 않는 것과 비슷합니다.
그런 체계는 원소에 대해서 아무 것도 알려주지 못합니다.
만약에 이런 시스템이 "언어가 아닌 언어"(impossible language)/비언어와 언어를 구분하지 않고 작동한다면, 이 시스템은 언어에 대해서 아무 것도 알려주지 못한다고 정의내릴 수 있죠.
그게 이 시스템이 작동하는 방법입니다. 일반화를 시키죠. 다른 시스템도 마찬가지에요.
그렇기 때문에 이 문제는 큰 문제 입니다."
[원문 접음]
제레미 칸:
개리(Gary Marcus)님께서는 이 시스템들이 어떻게 실패하는지 실험을 해보셨죠?
어떤 종류의 실패를 발견하셨는지 알려주실 수 있을까요?
개리 마커스 (Gary Marcus) :
(1) 노암 촘스키와 전 이 주제에 관해 지난 몇 개월간 의견을 주고 받았습니다.
제가 부정적인 부분에 대해서는 노암이 너무 좋게 이야기 한다고 했던 부분이 있는데
이 경우에는 제가 노암이 너무 좋게 얘기해주는 부분도 있는 것 같네요.
노암은 시스템이 약한 부분에 파라미터/매개변수(Parameter)를 늘리면 어쩌면 그걸 해결하는데 도움이 될지 모르겠다-고 했죠? 전 거기에 대해서 좀 더 부정적인 의견을 가지고 있습니다.
(2) 이런 시스템이 가지고 있는 문제들에 대해서 얘기해보죠
달리(Dall.E )에게 빨간 큐브 위에 파란 큐브를 그려달라고 하면, 달리는 파란 큐브 위에 빨간 큐브를 그려주기도 합니다.
언어에 대해 가장 기초적인 지식은 우리는 언어의 순서에 의미를 부여한다는 거죠. (생략) 하지만 이 시스템들은 언어 순서의 관계와 그 아래 깔려있는 의미를 이해하지 못합니다.
또 다른 문제의 예를 들면, '여자를 쫓고 있는 남자', 혹은 '남자를 쫓고 있는 여자'를 그려달라고 하면, 그냥 랜덤하게 결과를 줍니다. 시스템(달리)는 그 구분을 하지 못합니다. 비슷한 걸 더 하는 것,요즘 (데이터) 스케일링이라고 불리는 것이 도움이 될 지 모르겠습니다.
이 시스템에는 아주 기초적인[펀더멘탈]들, 세상에 대한 이해, 물건들이 어떻게 작동하는지, 어떤 사물을 묘사하는 지 등 결여되어 있습니다.
[영어원문 접음]
Sure. And usually, also, Noam and I had this interchange over the last few months, where he tells me that I am too nice when I am negative about AI,
in this case, there's a certain way in which I thought he was too nice.
so, he said, that in the ways in which these systems are too weak, just adding more parameters, MAYBE that will help. And there, I actually take a darker view, maybe than, Noam does.
The kinds of problems these systems have are :
Dall-, if you tell it to draw a blue cube on top of a red cube. It might just give you a Red Cube on top of Blue Cube, So one of the most basic things about language is that we put together meanings from the orders of words. This goes back to Fraga and even further, these systems don't understand the relation between the orders of words and their underlying meanings.
Another version of this system, something like draw a picture of a man chasing a woman, or draw a picture of a woman chasing a man, and the system is basically a chance, it really can't tell the difference.
And it's not clear that just adding in more of the same what people call scailing today, is actually going to help.
I think there's something fundamental missing from the systems which is a understanding of the world, how objects work, what objects it's describing.
[글쓴이]
잠깐만요. 챗GPT가 말을 그렇게 잘 알아듣는데 같은 Open AI사의 달리(Dall.E)는 어떻다구요?
의심많은 전 바로 실험을 해봤습니다. 심지어 달리 2 입니다.

테스트를 해보니 정말 요청을 이해하지 못합니다.
특히 전치사가 들어가는 문장들에 대해 공간에 대한 이해가 없다는 게 느껴졌어요.
Dall.E 2 말귀 테스트
예시1
일단 위 인터뷰에 나온 내용의 문구대로 해봤습니다.
요청: 빨간색 큐브(정육면체) 위에 있는 파란색 큐브를 그려줘.
결과: 파란 선에 빨간 색 색칠, 빨간 큐브 옆에 있는 파랑 큐브, 파란색 큐브 위에 있는 빨간 색 큐브, ...
딱 제가 요청한 빨간 큐브 위의 파란 큐브만 안 그려줬습니다.
점수: 0점

뭐.. 오류가 있을 수 있으니, 다시 실험해봤습니다.
예시2
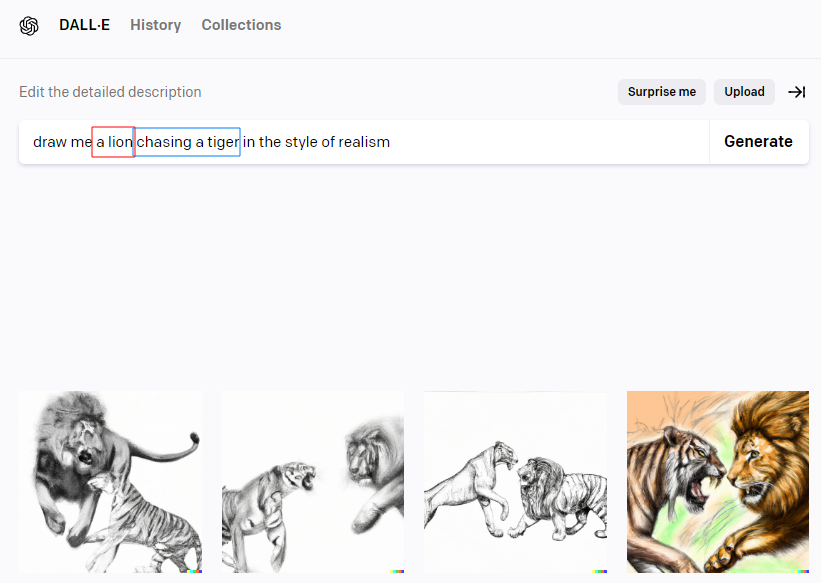
요청: 호랑이를 쫓고 있는 사자를 그려줘. 현실주의 느낌으로.
결과: (아래) 그냥 사자랑 호랑이가 대치하고 있는 구도의 그림을 그려줌
점수: 0점
예시 3
요청: 숫자 4위에 있는 3 그려줘
결과: 3만 그려주고 4는 없음..
점수:0점

그 외 총 12개에 대해서 진행해본 결과는 접음 처리 합니다.
1번의 질문에 4개의 답안을 제시하니 4개의 그림이 다 맞으면 1점, 4개 중에 하나만 맞으면 1/4, 0.25점으로 계산했습니다.
총 득점은 0.25+0.25+0.5=1점
12개에서 총 1개 맞춘 꼴입니다.
백분율로 하면 정답률 8.33%.
From-To, Tall-Short, 숫자(numbers)에 대한 개념은 이해하지 못하는 것으로 보입니다.
예시4:
요청: 고양이를 무는 개를 그려줘
결과: 고양이에게 뽀뽀해주는 멍멍이 그림, 대치 중인 개와 고양이 그림, 사이좋은 개와 고양이 그림, 고양이를 무는 것 같은 멍멍이 그림으로 보이는 그림 하나

점수: +0.5 (2/4) 포인트 획득
예시5
요청: 못 생긴 남자에게 프로포즈 하는 예쁜 여자 그림 그려줘
결과: 실패
점수: 0점

예시 6
요청: 3D 그래픽으로 예쁜 여자가 못 생긴 남자에게 프로포즈하는 거 그려줘
결과: 4개의 그림 중, 3개의 그림 모두 남자가 여자에게 프로포즈하는 그림을 생성. 한 개는 의미불명.
※ 언어를 통계적으로 분석한다길래 일부러 고정관념의 반대의 그림을 요청해봤어요.
점수: 0점

예시7.
요청: 하늘에서 땅으로 추락하는 비행기 그림을 연필로 그려줘
결과: 그림 4개 중 3개는 이륙하는 비행기, 1개는 하강 중인 그림.
점수: 0.25점

예시8.
요청: 파란 눈의 매력적인 여성 5명과 빨간 눈의 고양이 세 마리 그려줘
결과: (1) 고양이 여섯마리 그림 1개 , (2) 고양이 일곱마리 그림 2개, 고양이 다섯 마리 1개
점수: 0
예시9.
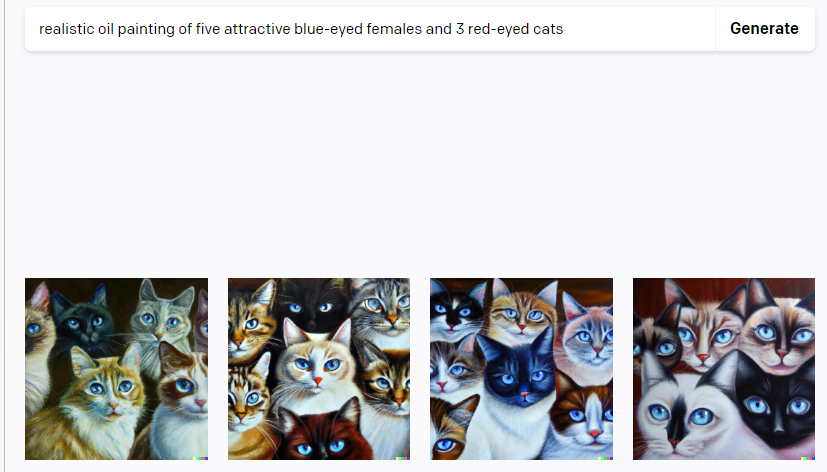
요청: 현실적인 유화 스타일로 다섯 명의 파란 눈의 예쁜 여자 그려줘
결과: 파란 눈 여자 여섯 명 그림 3개, 파란 눈 여성 다섯 명 그림 1개
점수: 0.25점
비고: 반쪽 자리 얼굴 2개는 하나로 계산하니...? 혹시..?

예시 10.
요청: 디지털 아트 스타일의 노란 눈의 소녀 일곱명 그려줘
결과: 파란 눈 소녀 여섯 명 이미지 2, 다섯명 소녀 중 한 명은 노란 눈인 그림 하나, 소녀 열명 중 5명은 노란 눈 (어떤 사람은 한쪽눈만 노랑)
점수: 0점
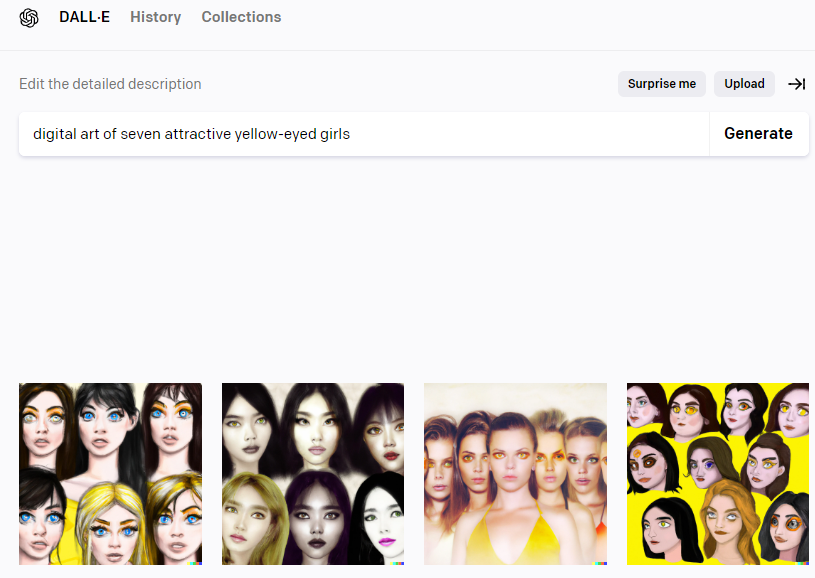
예시 11
요청: 인상파 스타일로 키 큰 여자 한 명과 키 작은 남자 한 명 그려줘
결과: 키 큰 남자, 키 작은 여자 그림 1개, 그 외 키가 똑같아 보이는 두 사람 그림 3개.
점수: 0점

예시12
요청: 파란색 일렉 기타 2대, 베이스 기타 3대, 사이버펑크 스타일로
결과: 베이스 기타 4대인 사진 하나, 일렉기타 3대인 사진 하나, 베이스 기타 3대 사진 하나, 일렉기타 2대와 베이스 기타 1대 인 사진 하나
점수: 0점
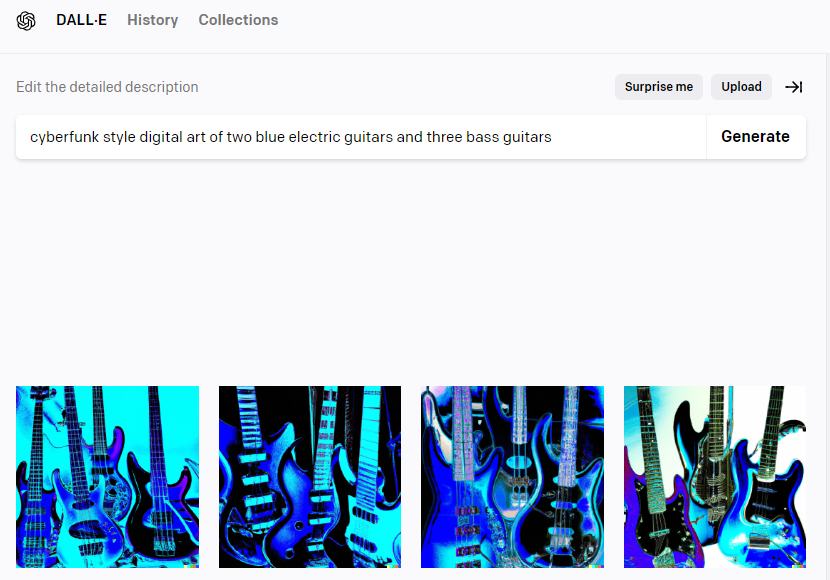
총득점: 1/12점 | 12개 문제 중 하나 맞은 걸로..
개리 마커스:
달리가 처음에 나왔을때, Open AI사의 샘 알트만(Sam Altman)이 말했죠.
AGI(범용인공지능/Artificial General Intelligence)는 정말 'wilde와일드'(대단/어마어마/굉장) 할 거라구요.
(그 때는) 저와 같은 과학자들에겐 접근권한이 제공되지 않고 있었어요.
지난 몇 개월 전에서야 접근가능하게 되서 보니 이 곳 저 곳 문제가 많았아요.
네, 예쁜 그림을 그려낼 수 있죠.
하지만 이 시스템들의 (인간) 언어에 대한 이해는 굉장히 얕습니다.
노암 촘스키의 관점에서 보면 언어에 대한 이해가 얕다면 노암의 평생을 바친 커리어 의 질문인 "인간 언어는 왜 이런가 ?" 에 도움이 되지 않는거죠.
노암이 말하는 건 이런 시스템이 인간의 언어와 다른 컴퓨터 언어를 연산할 수 있고, 뭐든지 배울 수 있다고 하지만, 어느 하나도 완벽하게 하지 못하고, 이 시스템들은 왜 우리가 특별한 피조물/존재인지 아는데 도움이 되지 않는다는 거죠.

제레미 칸:
노암 선생님(?), 이 시스템들이 좋은 엔지니어링이지만 좋은 과학은 전혀 아니다 라고 하셨다고 알고 있는데, 그게 무슨 뜻인지 알려주실 수 있을까요? 왜 이 과학이 실제로 유효하지 않은지요
노암 촘스키:
엔지니어링 업적에 대해 얘기해보죠.
전 난청이 있어요. 그래서 여러분들이 얘기하는 것의 대부분을 듣지 못하죠.
지금 라이브-트랜스크립션, 캡션을 읽고 있어요.
이런 것에 대해 전적으로 지지 합니다.
이건 과학적 흥미가 전혀 없는 '순젆 힘으로' 이뤄낸 거죠.
하지만 좋아요. 만족합니다.
직접 손으로 할 필요 없이, 길에서 눈을 치워주는 기계에 만족합니다.
여기에 대해 비평할 건 없습니다.
이건 멋지다고 생각합니다.
종종 엔지니어링 성과는 과학에 기여 합니다.
예를 들어 망원경은 갈릴레오가 어떤 것들을 발견할 수 있도록 도왔죠.
그게 없이는 발견할 수 없었을 겁니다.
(갈릴레오의) 망원경과 마찬가지로 딥러닝(Deep Learning)을 통해서 엔지니어링 성과를 얻은 것도 있습니다.
(알파폴드와 같이)프로틴 폴드(Protein Fold)의 모양이 어떻게 나오는 지에 대한 아주 유용한 결과를 도출한 것들도 있죠. 좋습니다.

하지만 과학은 다른 것에 신경을 쓰죠.
이 세상이 어떤 지 알아보려 하는 거죠.
어떻게 하면 유용한 것을 만들 수 있을까가 아니라.
물론 유용한 것을 만드는 건 잘못 된 게 아닙니다.
하지만 이 세상에 대해 알아가는 프로젝트는 그것과는 다른 거죠.
개리가 말한 제가 너무 '나이스'한 평가를 했다는 부분에 대해서, 전 수긍할 의지가 있습니다. 1,000여개의 매개변수/파라미터를 추가하면 결과를 도출할 수도 있다고 했던 거에 대해서요. 아닐 수도 있겠지만.
GPT 시스템과 그 부류의 다른 시스템들은 천문학적인 량의 데이터 속에서 표면적인 규칙을 파악하고 데이터랑 비슷한 걸 생산해낼 수 있습니다.
하지만 그건 언어가 아닌 언어와 인식의 모든 원칙들을 위배하는 다른 데이터를 가지고도 같은 결과물 (혹은 더 나은 결과물을) 생산해낼 수 있습니다.
그래서 첫째로 언어와 인식에 대해서 아무 것도 알려주지 못하고,
만약 이게 어떤 이바지를 하냐고 묻는다면, 이 경우에는 아무 공헌도 안 보인다고 해야겠네요.
GPT의 쓸모가 어떤 학생들이 과제나 시험을 속이는 거 외에는 어디에 있는 지 제 눈엔 보이지 않습니다.
I don't see what point there is to GPT except for maybe helping some students fake an exam or something.
과학에 대한 공헌도 없고, 엔지니어링에 공헌하는 바도 없고, 제가 볼 땐, 이건 캘리포니아의 많은 에너지를 낭비하는 겁니다.
[영어 원문 접음 처리]
Kahn:
Interesting. Noam, I know you've sort of said that these systems, are maybe good engineering but not very good science at all. Can you explain what yoou meant by that. and Why you think, you know, the science here isn't really valid.
Noam:
Well, take a engineering achievement. so I happen to be hard of hearing. So I can't hear most of what you're saying. I'm reading live transcription. captions. It's pretty helpful. I'm all in favor of it. It's achieved by a brute force, no scientific interest. But it's fine. I am happy with it.
I am happy with a snow plow that clears the streets, so you don't have to do it by hand. I don't see anything I have, no criticism with that.
I think it's great. Sometimes, the engineering achievements can contribute to science.
So a telescope for example, made together they allowed Gallileo to dsicover things. He couldn't have discovered without it. Well, that's fine.
There are some engineering achievements in with the Deep Learning approaches that have been like a telescope.
So they've apparently produced helpful results with regard to protein folding look, massive computation beyond and computation.
So that's good.
But science is different concern. You're trying to understand what the world is like. Not, how can I make something useful. nothing wrong with making useful things, but the project of trying to understanding what the world is like, is different.
So turning to Gary's point, I'm perfectly willing to concede that I've been too nice and thinking that if you had a thousand parameters, maybe you'll get somewhere. Maybe you won't.
My concern is different.
If the system doesn't distinguish what's the actual word(?) from non- actual word, it's not telling us any. Just as in the case of souped-up periodic table.
The GPT systems and others like them can find superficial regularities in astronomical amounts of data and produce something that looks more or less like what their data was.
But it can do exactly the same thing, even better often with data that violates all the principles of language and congnition. so they're, first, telling us nothing about them, you might ask whether it's making an contribution, actually in this case, I don't really see any.
I don't see what point there is to GPT except for maybe helping some students fake an exam or something.
But so, it doesn't seem it has no scientific contribution, doesn't seem to have any engineering contribution. so as far as I can see it's basically a way of wasting a lot of the energy in California, right.
[글쓴이]
노암 촘스키 님의 의견은 시니어 학자의 '라떼는 말이야~'의 느낌인 건지, 학자로서 학문에 대한 열망으로 비평하고 있는 건지, 애매한 느낌이 없잖아 있는 것 같은 인사입니다.
챗GPT의 매개변수를 추가하면 더 똑똑해지는 건가봐요.
그래서 챗GPT의 매개변수에 대해 물어봤습니다.
모델에 따라 다른데, 1억 2,500만 개 부터 130억개 까지 구분이 되는 군요.

제레미 칸:
어, 고무적이군요. 좋은 지적인 것 같습니다.
이제 개리에게 물어보고 싶습니다.
이것들이 어떤 부분에서 유용한 도구라고 하면, 이 도구가 실체보다 더 뛰어난 능력이 있다고 생각하게 해서 발생하는 위험이 있을까요? 이 (챗GPT)열풍/광풍 속에 위험이 있을까요? 어떤 의견이 있으신가요?

(1) 첫번째는 인공지능에 대해 잘못된 길을 걷고 있는 거죠.
인공지능을 향한 바른 길은 좀 더 인간에 대해 알아가는 과학이죠.
노암이 말한 것 처럼요.
우리는 지금 극대값(local maximum)에 있습니다.
좋아보이는 게 있지만 필요한 깊이가 없어요.
그리고 이게 인간이 어떻게 언어를 이해하는 지, 인간이 이 세상을 어떻게 이해하는 지, 인지과학에 필요한 산소(관심)를 뺏어가고 있습니다. 이 장난감(인공지능)을 가지고 노는 게 너무 재미있어서요. 하지만 이게 젊은 대학원생의 에너지를 많이 가져갑니다.
만약 언어학과 GPT3와 관련된 일을 해서 돈을 많이 받는 것 중에서 고르라면 GPT3를 고르겠죠.
하지만 전 우리가 사람들이 생각하는 것보다 훨씬 짧은 미래를 가진 기술에 휩싸인다면 그건 근시안적이라고 생각합니다.
인공지능의 역사를 돌아보면 이런 유행은 계속 있어왔어요.
엑스퍼트 시스템(Expert Systems), 서포트 벡터 머신(Support Vector machines) 같은.
한동안 엄청난 인기를 끌었지만 지금 청중 여러분들은 들어보지 못했겠죠.
우리는 좀 더 안정적인 게 필요합니다.
그저 또다른 유행/열풍은 저희에게 큰 도움이 되지 않을 겁니다.
(2) 또 다른 위험은 우리가 현재 가지고 있는 시스템이 하는 건 과거 데이터를 영속시킵니다.
이 시스템은 이 세상(현실)을 이해하지 못합니다.
예를 들면 시스템이 성차별주의자이고 인종차별주의자인 거죠.
시스템이 그렇게 개발된 게 아닙니다. 하지만 과거 데이터를 그저 복사하기 때문이죠.
시스템엔 평등에 대한 가치가 없습니다. 그래서 과거의 편견을 영속시키죠.
또 다른 예로는 이 시스템들은 세상에 대한 모델이 없기 때문에 무분별하게 거짓말을 합니다. 물론 시스템이 말 그대로 거짓말을 하는 건 아닙니다. 시스템에는 의도라는 게 없으니 악의도 없습니다.
이 시스템들은 역정보(misinformation/잘못된 정보)를 생산해냅니다.
그리고 그건 수년 내 세상을 바꿀 겁니다. Troll Farm (트롤팜: 악의적 댓글부대)이 얼마나 많은 양의 역정보를 만들어낼 수 있을까요. 거기에 대한 댓가는 민주주의 절차를 피폐하게 할 거라고 생각합니다.
그래서 우리에게 괜찮아 보이고 문법적으로 맞는 문장들을 만들어내는 시스템이 있지만 그 시스템이 만약에 '명상 뒤에 양말을 먹는 게 왜 좋은 지' 에 대한 내용을 만들어내고, 그게 그럴싸하게 들리는 문장이면.. 이런 내용을 자기 전에 웹사이트에서 읽고 믿게 되면요.
이걸 또 스케일을 키워서 하게 되면, 50만 달러로 커스텀 버전의 GPT3를 만들 수 있으면, 트롤팜(악성댓글부대)에게는 훌륭한 투자가 되겠죠. 하지만 그건 이 사회에는 큰 문제가 됩니다.
그렇기에 꽤 구체적인 위험이 도사리고 있습니다.
또 하는 다른 작은 위험들도 있죠.
예를 들면 사람들이 무인차량에 많은 돈을 쓴다거나...... 이건 잘 풀리고 있는 것처럼 보이지 않아요.
20년 후엔 될지도 모르겠어요. 하지만 우리가 (일론)머스크가 5-6년전에 우리에게 약속한 '목적지를 입력하면 일상생활에서 쓸 레벨5 자율주행차량은 아닐 겁니다.
그건 이뤄지지 않을거에요. 천억 달러가 그 산업에 투여되고 있는데 돈이 낭비되고 있습니다.
전 투자자들이 돈을 잃는 것보다는 민주주의가 마주하는 위협이 더 걱정됩니다만, 이 역시 이 (인공지능 열풍의) 부산물인거죠.
제레미 칸 :
이 실패의 모드에 대해 이해를 하지 못하는 것에 대한 위험은 없나요? 최근에 시스템에 접근가능하게 되신 후 언어를 이해하지 못한다는 것과 같이.. 마커스가 발견하신 것들이요이 열풍을 믿고, 이 시스템이 실체보다 더 능력이 있다고 믿게 되는 것에서 오는 위험은 없나요?
개리 마커스:
2023년 와이어드(Wired)에 곧 실리게 될 예측이 있습니다.
2023년은 이런 시스템이 사망 원인으로 기록될 첫 해가 될거라고 예상합니다. 이런 시스템이 사용자에게 자살을 하라고 한다거나, 이 시스템(과의 대화를 통해) 을 사랑하게 됐는데, 시스템이 사랑을 주지 않는다거나, 아니면 락스와 하수구청소액을 섞어서 먹으라고 한다거나 해서요.
사람들은 이 시스템이 믿을만해보이니까 믿게 되는데 ,
이 시스템들이 하는 건 , (여기에 대해서 아직 얘길하지 않았군요), 일종의 자동완성(auto-complete) 같은 겁니다. 우리의 폰이 다음 단어를 추측하는 것처럼요.
GPT는 스테로이드 복용한 자동완성Auto-Complete 같은 겁니다.
하지만 그 이상의 것이라는 환상을 줍니다. 그리고 사람들은 이 시스템에 빨려들어와 나쁜 조언을 받게 되는 거죠.
제 생각엔 내년부터 이런 시스템들이 보급되고 저렴해지는 걸 볼 수 있을 겁니다.
제레미 칸:
노암 선생님, 이런 시스템들이 어떤 기여도 하고 있지 않다고 얘기 하셨는데. 이런 LLM (Large Language Model)이 선생님께서 평생을 바치신 언어학에 대한 이해에 기여하는 것은 조금이라도 있을까요?
노암 촘스키:
하나도 떠오르지 않네요.
(중략)
최근에 나오는 연구들보면, Reddit 과 다른 여러 데이터베이스에서 슈퍼 컴퓨터를 통해 단어사용빈도에 대한 연구가 있었습니다. Ocaasion 이란 단어가 molecule이란 단어보다 훨씬 자주 사용된다는 거죠. 그리고 그 이유를 더 많은 영역에서 사용되기 때문이라고 설명했습니다. (비꼼) 그걸 누가 상상이나 했겠어요.
(생략)
제레미 칸:
우리가 인지과학에 대해 알고 있는 많은 것들이 딥러닝과 관련된 열풍 때문에 무시되고 (활용되지 않고) 있다고 생각하는 걸로 알고 있습니다.
개리 마커스:
지금 사람들이 하고 있는 걸 보면 언어학 수업을 하나라도 들었는 지 궁금합니다. (중략)
고전적인 방법으로 언어생성 모델을 만들려면, 먼저 표현하고자 하는 뜻(meaning)으로 시작해서 그걸 단어(word)로 번역합니다. 언어 이해에서는 이해하고자 하는 한 문장(sentence)에서 시작해서 그걸 의미로 번역합니다.
GPT3는 그런 걸 하고 있는 게 아니에요.
하지만 사람들은 그걸 알아채지 못합니다. 그런 부분을 의식하지 못합니다.
(1) GPT3가 하는 건 단어들의 배열(sequence)가 있고, 그 다음 단어가 뭐가 될지 예측하는 겁니다.
GPT3는 로데오에서 타는 말과 같아요. 강력합니다. 문법적으로 맞는 것들을 생성해내기 때문에 흥미롭지만, 유저가 원하는걸 주는 지는 완전히 다른 문제이죠.
팜-세이캔(PaLM-SayCan)이라는 구글에서 나온 논문이 있습니다. GPT3를 로봇에 탑재했었죠.
3/4은 제대로 작동합니다. 어마어마하죠. 하지만 나머지 1/4은 제대로 작동하지 않아요.
만약에 이 로보트가 당신의 할아버지를 침대로 옮겨준다고 상상해봅시다. 로봇에게 그렇게 해달라고 얘기합니다. 하지만 75%의 경우는 그렇게 하고, 25%의 경우는 할아버지를 떨어뜨리는 거죠. 그럼 안 되겠죠.
인지과학은 우리에게 알려줍니다. 기초적인 거죠. 만약 뜻을 문장 안에 맵핑하거나, 그 반대로 해야하는 거죠.
하지만 (요즘) 사람들은 "우리에겐 이만큼 데이터가 있으니깐 그런 거 안해도 되요" 라고 하죠.
아니에요. 그건 정말 필요한 거고 아직도 해야합니다.
(2) 또 다른 예를 들자면, 우리에겐 많은 지식이 있습니다.
대학교에 가거나, 다섯살 때 책을 읽든지 간에, 우리는 세상으로부터 언어로된 상징적 지식(verbal symbolic knowledge)을 흡수합니다.
50년 전의 신경망(neural networks)와 지식기반(knowledge-based) 접근방법에 대한 재밌는 정치(?)가 있었죠.
지식 기반의 접근방법은 가치가 있었지만 문제도 있었죠, 30년 전에요.
지금은 이 모든 걸 '지식' 없이 진행하고 있습니다. 그게 무슨 뜻이냐면, 위키피디아에 많은 지식이 있는데 그걸 이 시스템에 넣는 방법을 모른다는 겁니다.
그리고 이 "통계적 흉내" 때문에, 미국의 대통령이 누구냐고 물으면, 도널드 트럼프라고 답변을 할 수도 있습니다. 시스템에 있는 데이터셋에 조 바이든 보다 트럼프의 예가 많기 때문이죠. 생각을 해서 바이든이 현재 대통령이고, 트럼프는 그 전의 대통령이었다고 말할수 있어야 하는데요.
사건의 순서와 시간에 대한 이해를 사용해야 합니다.
인지과학은 이런 걸 생각하죠. 담화(discourse) 모델을 합쳐서, 우리가 이야기하는 게 뭔지, 어떻게 얘기하고 있는지에 대해 생각하는 등, 많은 아이디어가 있습니다.
(3) 또 아직 우리가 얘기 하지 않은 것 중에, 제가 노암 촘스키부터 배운 아주 근본적인게 있죠. 노암도 플라톤으로 부터 배운 거죠. 생득성(Innateness - 본유적인/타고난 본질적인 것)이란 우리의 생각mind에 빌트인/타고난 거죠.
우리가 언어를 배울 때, 우리는 "빈 서판 (The Blank Slate/Tabula Rasa)"에서 시작하지 않습니다. 노암 촘스키는 여기에 대해 수년간 주장해왔죠.
전 아직도 그게 맞다고 생각합니다.
그게 우리가 보고 있는 달리Dall.E의 실패에서 (그걸 지지 하죠).
만약에 빈 서판(blank Slate)에서 시작해서 언어를 이해하지 못한 채 그저 통계들을 축적하면,, 두 분께 어제 보내드린 논문과 마찬가지로 (테슬라의) 비전Vision 과 비슷한 결과를 보여줍니다.
행동을 구분/라벨링 하는 모델들이 있습니다. 고개를 끄덕인다거나. 시각적 라벨링을 하는 거죠.
그리고 (이 바닥에서)언제나 존재하는 신화/환상(myth)는 만약 시스템에게 충분한 데이터를 주면, 제대로 된 (인식이) Emerge, 생겨나서 이 세상을 이해할 수 있을 거라는 거죠.
우리는 실험실에서 10개월 아기가, 어떤 실험에선 4개월 아기를 기준으로 (세상의) 물리학적 특성을 (얼마나) 이해할 수 있는 지를 벤치마크로 만들었습니다. 물건이 떨어진다거나, 물건을 숨긴다거나, 아이들은 결국 그걸 찾아내죠. 하지만 이런 시스템은 그걸 이해하지 못합니다.
앨런 인공지능 연구소 (Allan AI Institute )와 일리노이 발달 심리학자와 제가 함께 (이런 내용에 대한) 논문을 발간했습니다.
충분한 데이터를 입력하면 인식이 생겨날 거라는 경험주의적 가설(Empricist Hypothesis) 입장에선 완전한 실패였죠.
저와 함께 협업한 발달심리학자들은 여기에 대해 많은 연구를 했습니다.
아이들은 세상의 사물들에 대해 아마 내제된 감각이 있는 것처럼 보인다는 거죠. 아무 것도 없는 상태에서 시작되지 않습니다.
(임마뉴엘) 칸트는 우리가 시간과 공간과 인과관계에서 시작한다고 했죠.
아마 맞을 겁니다. 우리는 거기서 시작합니다.
사람들은 계속 이 가설을 쫓지만, 여기에 관한 인지과학을 무시하고, 계속 데이터만 사용할 거라고 하죠. 75%는 작동하니깐요.
그래서 진보하고 있다고 생각합니다. 하지만 75%는 충분하지 않아요.
무인차량 산업에서 우린 그걸 보고 있어요.
(해결책에) 가까워진다는 게 문제를 해결하고 있는 것 같지 않죠.
그게 우리가 여기서 보고 있는 (문제) 입니다.
제레미 칸 :
개리, 제가 알기론 지금의 인공지능 광풍과 거품, 그리고 우리가 원하는 걸 제공하지 못하는 것에 대해서 불구하고 인공지능의 앞날에 대해서 여러 생각이 있으신 걸로 알고 있습니다. 어떤 게 앞으로 가야할 길일까요?
개리 마커스:
여러분께서 나중에 아카이브에서 읽으실 수 있는 Next Decade in AI 란 글이 있습니다. 이 글에서 4가지를 지목합니다.
(1) 신경상징 인공지능( NeuroSymbolic AI)이라고 부르는 게 있습니다. 전통적인 AI와 현재 유행하는 신경망을 합친 거죠. 이 두 개의 합성물을 찾으려는 시도 입니다. 두 모델다 가치가 있으니깐요.
신경망/뉴럴 네트워크는 데이터로부터 학습하는 것을 잘하지만 추상적 지식을 얻는 것을 잘 못합니다. 그리고 과거의 상징 모델은 추상적 지식을 쌓는 것을 잘하지만 데이터로부터 배울 수 없구요.
그게 첫번째 단계입니다.
(2) 두번째는 우리는 기계가 해석할 수 있는 대량의 데이터베이스가 필요합니다. (현재의 흉내 내는 식으로 해결해나가고 있는 방법은 충분히 풍부하지도 않고 추상적이지 않습니다.
제가 지금 물병을 들고 있는지 보이지 않는 상황에서도 만약 제가 아까 물병을 들고 올라오는 걸 봤다면 그 물병이 넘어지면 이 무대 위에 물이 있을 걸 알 수 있습니다. 지금 이 상황에 있는 이 물병을 본적이 없더라도요.
그래서 제가 지금 이 물병을 얘기할 때, 여러분께서 보지 못하더라도 이 물병에 대한 내재적 대표(상징)을 유지하고 있는 거죠.
그게 완벽하진 않겠지만, 이 세상에 있는 것들에 대한 그런 상징을 가지고 이성적으로 사유하는 거죠.
이런 것들이 현재의 인공지능에서 표현되지 않고 있는 인지과학에서 근본적인 생각입니다. 그리고 거기에 대한 댓가를 지불하고 있죠.
제레미 칸:
노암 선생님, 개리님이 말하는 것들이 (인공지능이) 나아가야할 길이라고 생각하시나요? 생득성에 대한 생각이 인공지능 시스템을 생각할 때 접목되어야 한다는 생각이요.
노암 촘스키:
제 생각엔 그게 우리가 나아가야할 옳은 길 입니다.
한 편 AI가 계속 발전하기 위해서는 다음 내용들을 고려해야 합니다.
우리가 인지능력을 획득하게 되는 기초에 대한 이해. 물론 이건 우리가 어느 정도 이해하고 있는 근본적 생득성의 속성을 포함합니다. 그리고 어떤 종류의 진화가 이런 능력을 제공했는 지에 대한 이해도 포함해서요.
(생략)
(예전에 ) AI는 인지과학은 구분되어 있지 않았습니다.
인공지능은 인지과학의 문제를 접근하는 방법의 하나였습니다.
연산이론과 물리장비/하드웨어들의 발전과 함께 지적으로나 기술적으로나 위대한 업적들을 이용해서요. 그걸 통해서 도입 할 수 있었던 겁니다.
그건 인지과학을 발전시키기 위해 좋은 방법 있었습니다. 과학의 일부분이었고, 그저 '장난감'을 가지고 노는 게 아니었죠.
(중략)
이하 영어 인터뷰 원문
원문)
Jeremy:
"Gary, I know you've thought that there's a lot of things we do know about cognitive science. that it is being ignored, sort of , by the current enthusiasm for Deep Learning. and ever larger deep learning systems.
Gary:
I look at what people are doing now. and I think, "have they ever taken a class in linguistics? so in linguistics you learn about the relationship between syntax and semantics for example. In between those in pragmatics.
If you build a language production system for example, in the classic way, you start with a meaning that you want to express, and you translate that into words. Or in language comprehension, you start with a sentence that you want to understand, and you translate that into a meaning.
Well, GPT3 doesn't do that. And people don't even realize it doesn't do that, people don't even notice that.
What GPT3 does is, here's a sequence of words, and it predicts the next word.
But let's say you want to talk to a user, you know what you want to say, well, GPT is like a wild bucking bronco, it's very powerful, it might produce something grammatically interesting, but whether it winds up giving you want you want is an entirely different matter.
and if you want to extract from it a model of the world, it doesn't really do that.
So there's this paper called. PaLM-SayCan, I think by Google, where they put GPT3 in a robot. It works three quarters of the time. and it's amazing. but a quarter of time, it doesn't work.
Now imagine that you want to put your grandpa in bed, and you want to tell the robot to do that. and three quarter times it does that. and one quarter time it drops your grandpa, like this is not good.
so cognitive science tells us we want for example, it's just a basic thing. but you want a map a meaning onto a sentence, or the other way around, people are like, I've got all this data and I don't need to do that.
Well, no, you don't . you really do still need to do that.
Another example is we have lots of knowledge, you know, you go to college and read books or when you're five you read books. You absorb verbal symbolic knowledge from the world.
And there's this funny politics that goes back 50 years about using Neural Networks verses a Knowledge based approach. It turns out the knowledge-based approach has some value but it had some trouble you know, 30 years ago.
So now we're doing all this stuff without knowledge, which means like you have all the knowledge, in Wikipedia, and nobody really knows how to put it into these systems.
and because they are statistical mimics, you ask a question like who's the president of the United Stats. And they might say Donal Trump, because in their data set, there are more examples of Donald Trump than Joe Biden.
Where if you want to be able to reason and say, well, Biden is now the president, Trump was the president before.
You want to use your understanding of sequences of events and time. Cognitive scientist think about this stuff, they think about things like discourse models putting together what it is that we're talking about how we're talking about it. There are lots of ideas.
==
another one that we didn't talk about yet, but which I learned from Noam, and which is really foudational. I know he learned it from Plato, is INNATENESS, the idea that something is built into the mind.
There's lots of reasons to think that when we learned language, we're not starting from a blank slate.
Noam has made this argument for years and years.
I think it's still true. and the failures that we're seeing, for example, with Dall.E, and I'll tell you about one another, if you start with a Blank Slate, that just accumulates statistics, you don't reallly understand language, the paper I have yesterday, which I sent to both of you guys, shows the same thing in Vision.
So there's some models that label activities, so it can say, you're nodding your head, those people are sitting out there. you can do some visual labeling, and the myth is always, the right things will emerge, which is kind of magic, it's like a Latin A.I word for magic, it will emerge when you give enough data, to these systems, that they will understand the word.
so we built a benchmark based on what 10 months olds do in the lab, or four months old for some of the experiment, understanding basic physics, like things drop, or if they hidden, you can still you know, find them eventually,
and these systems don't understand at all.
The Ellen AI institute and some developmental psychologists from Illinois, and I published this paper, it's a complete failure of the Empricist Hypothesis, that if we just give a lot of data, that cognition will emerge.
And developmental psychologist have done lots of work, Liz Felke, in particular- but many people Renne Byers, one of our collaborators on this paper, have done, lots of work. - that children, seem to have probably innate sense of how objects exist in the world, like we don't start with nothing.
Kant said we start with Time and Space and Causality.
He's probably right. We probably start with those things.
And over and over people keep pursuing this hypothesis, that ignores the cognitive science around that, and say we'll just use all the data.
And because it works like 75% of the time, they think they 're making progress. 75% of the way it's not enough. We saw that in the driverless car industry, right.
You know, getting close, doesn't really seem to solve that problem. and that's we're seeing here.
Jeremy Kahn:
Gary I know you have ideas about how you would go forward if today's AI despite al the hype around it, is not delivering what we want. What would ? What would be a path forward?
Gary:
I have an artical called Next Decade in AI, which people can read later in archieve, but it points to four things.
(1) what we call NeuroSymbolic AI, which is putting together this tradition, of Neural Networks that's popular now, with the old-fashioned AI, trying to find some kind of synthesis between, the two.
Because they each have some values.
The Neural Networks are good at learning from data, but they are not very good at abstract knowledge. And the old symbolic stuff is good with abstract knowledge but not learning from data.
so that's the step one.
Step two, we need to have a large database of machine interpretable knowledge, so all these things kind of fake their way through but knowledge is never rich enough and abstract enough.
so you know, if I have bottle you can't see it but if you saw me bring it up, if I knock it over, there's probably going to be water on this stage.
even if you haven't seen this particular bottle in this configuration.
a very general abstract knowledge. and that's crucial, I think, to any general intelligence, then we can reason about things, we can make inference about them , and we have cognitive models of the world.
so you know, right now that I mentioned it that this bottle is here even if you can't see it. So you're maintaining an internal representation of the stuff that's out there.
It might be imperfect, but you have a representation in your head of the things out there in the world. You reason over.
These are foundational ideas in Cognitive science, and they are not represented in current AI. And we're seeing the cost of that.
Jeremy Khan:
Noam, do you think that what Gary's saying is probably the way forward? Some of these ideas about innateness should be incorporated into the way we think about AI system.
Noam:
I think those are good ways to proceed.
But I also think that if AI wants to proceed it should take into account:
What has come to be understood about the basis for acquiring our cognitive capacities, which of course are, do involve fundamental innate properties we know have some understanding of them.
And even some understanding of whether the kind that evolution would provide.
We should recall that back in the early days. The days I happened to favor myself.
AI was basically not distinct from cognitive science.
It was just one of the ways of approaching the problem of the cognitive science using achievements great achievements that had been made, both intellectually, and technologically. with the development of the theory of computability, and its physical devices.
that were able to implement it. This was a great way to advance cognitive Science. as long as you were part of science not when you're playing with toys.
we're tying to impress science reporters and journals. But when you're pursuing the message of science, in the cases that Gary was discussing.
Taking in to account the kind of discoveries of !#$!@# , the innate basis for our ability to maneuver in the world.
If you're working on language, the end thought which are indistinguishable, then you look at what has been discovered about innate basis for acquisition of language.On the basis of virtually no evidence that has been shown by now, been experimental work a lot of it, by the late @#$@# claytman others that would show that a child aquires language the way it walks. you know.
It's just sitting there waiting to be triggered by some stimulation then it all comes out.
Well, you want to study introducing such understanding into the methods of AI, it could lead to carrying forward the earlier programs which I thought were on the right track, of using the achievements of intellectual achievements, technological achievements as a way of carrying cognitive science forward, in its effort to understand what the world is like. In this case, what our minds are like.
Jeremy:
Great. Well, we're out of time. But I want to thank Noam Chomsky and Gary Marcus for coming here and debunking a bit of the hype around today's AI. and also pointing forward to some ways we might be able to take the technology forward.
인터뷰 영상 외에도 최근에 노암 촘스키가 쓴 글(링크)에는 좀 더 정제된 표현으로 정리되어 있습니다.
[번역]
인간의 의식(mind/정신)은 ChatGPT와 같은 통계적 패턴 매칭 시스템과는 달리, 수백 테라바이트의 데이터를 과식하고 가장 가능성이 높은 대화 응답 또는 과학적 질문에 가장 확률적인 답변을 추론하는 것이 아닙니다.
오히려 인간의 의식은 작은 양의 정보로도 놀랍도록 효율적이고 우아한 시스템으로 작동합니다.
인간의 의식은 데이터 포인트 사이의 단순한 상관 관계를 추론하는 것이 아니라 설명을 만들기 위해 노력합니다.
예를 들어, 언어를 습득하는 어린 아이는 '미세한 데이터에서 무의식적으로, 자동으로, 빠르게 문법을 발전시키고 논리적 원칙과 매개 변수로 이루어진 놀라운 복잡성의 시스템인 문법'을 개발합니다. 이러한 문법은 인간에게 복잡한 문장과 일련의 사고를 생산할 능력을 부여하는 타고난 유전적 설치되어 있는 "운영 체제"의 표현으로 이해할 수 있습니다.
실제로 이러한 프로그램은 인지적 진화의 비인간적 단계 (혹은 인간의 전前단계)에 머무르고 있습니다.
그들의 가장 깊은 결함은 어떤 지능에서든 가장 중요한 능력의 부재 입니다.
"그런 것, 그랬던 것, 그럴 것" 묘사와 예측에 관한 것과 '그런 것, 그럴 수 있는 것과 그럴 수 없는 것".
(번역하기 너무 어려운 원어 표현: to say not only what is the case, what was the case and what will be the case — that’s description and prediction — but also what is not the case and what could and could not be the case)
이것들이 설명의 재료이며 진정한 지능의 표시입니다.
[기사원문 접음처리]
The human mind is not, like ChatGPT and its ilk, a lumbering statistical engine for pattern matching, gorging on hundreds of terabytes of data and extrapolating the most likely conversational response or most probable answer to a scientific question. On the contrary, the human mind is a surprisingly efficient and even elegant system that operates with small amounts of information; it seeks not to infer brute correlations among data points but to create explanations.
For instance, a young child acquiring a language is developing — unconsciously, automatically and speedily from minuscule data — a grammar, a stupendously sophisticated system of logical principles and parameters. This grammar can be understood as an expression of the innate, genetically installed “operating system” that endows humans with the capacity to generate complex sentences and long trains of thought.
Indeed, such programs are stuck in a prehuman or nonhuman phase of cognitive evolution. Their deepest flaw is the absence of the most critical capacity of any intelligence: to say not only what is the case, what was the case and what will be the case — that’s description and prediction — but also what is not the case and what could and could not be the case. Those are the ingredients of explanation, the mark of true intelligence.
3. 인공지능에 대한 환상의 근원
[글쓴이] 1부에서 살짝 언급되었던 트랜스휴머니즘이나 인공지능의 특이점 singularity' 에 대해서는 이번 조사를 통해 처음으로 생각해보게 되었습니다.
사실 인공지능에 대한 포스팅을 하기 전에는 진화론에 대한 공부를 하고 균형적인 시선을 갖고자 여러 강의를 듣고 있었습니다. 그 무렵 지인의 초등학생 아들이 진화론 때문에 기독교를 믿을 수 없다는 얘기를 했다고 들었거든요.
그러던 중 챗GPT를 써보고, 관련 강의를 여러개 듣던 중, AI의 개발에 뒤에 깔려 있는 언어학적, 철학적, 진화론적 전제를 발견했습니다. 그래서 인공지능을 먼저 다룬 후, 진화론에 대해 이야기 하는 걸로 노선을 변경했죠.
생명의 기원을 이야기 할 때, 무신론적 세계관은 아주 아주 단순하게 풀어쓰면 아래의 공식으로 요약됩니다.
화학 원소들 X 긴 시간 X 우연
= 생명의 탄생
단세포 생물체가 고등생물로 진화하는 것에 대해서 공식화하면 이렇게 되구요:
단세포 X 긴 시간 X 진화론적 매커니즘(자연선택+무작위 돌연변이)
= 고등생물
인간의 "의식mind" 혹은 "인지능력cognitive ability" 의 출현/발현에 대해서도 진화론적 해석에는 비슷한 것이 존재했었나봅니다.
지성이 없는 생명체 X 긴 시간 X 진화론적 매커니즘
= 지성 있는 생명체
그런 인식의 기원에 대한 철학적 전제가 현재 유행하는 인공지능의 개발 트렌드에 기반이 되고 있었던 것 같아요.
LLM(Large Language Model) 에서는 아래 공식으로 요약되는 기대를 가지고 있나 봅니다.
다량의 데이터 X (딥러닝+패턴 인식) X 긴 시간
= 지성의 출현
= AGI 혹은 특이점의 출현
인간의 지성의 시작에 필요한 필수요소가 물리적인 신체 기관, 그리고 시간과 경험 뿐이라고 가정하는 겁니다.
그렇게 전제할 경우, 약간의 기능 X 다량의 데이터 가 가공할만한 인공지능을 만들어 낼 수 있다고 가정해도 합리적인 거죠.
결국 어떤 전제가 옳은가 - 가 현재 추세의 결론을 통해 드러날 지도 모른다는 생각을 하게 됐습니다.
( 물론 가장 아이러니한 것은 설사 그런 실험을 통해 '인공지능에게 정말 '인식'이라고 부를 수 있는 것이 탄생한다고 해도, 결국은 '지성'이 지성을 탄생시킨 것이기 때문에 진화론적 입장에 도움이 되는 부분은 없다고 생각합니다.
3. 인간의 인지능력에는 분명 패턴을 인식하고 카데고리화 시키는 것 이상의 개념화가 존재하는 것 같습니다. 저희가 경험하는 것들을 데이터라고 했을 때, 우리는 그 데이터 이상의 것들을 추론하고 예측하고, 유사한 상황 혹은 다른 상황에도 그걸 적용하여 응용할 수 있죠.
개리 마커스의 다른 토론에서는 테슬라의 호출/서먼/Summon 기능이 보여준 우스운 사례가 언급됐었습니다.
공항에서 서먼 기능을 사용했는데 테슬라 차량이 자가용비행기/전세비행기에 들이박은거죠. (기사링크)

생각해보면 그럴 수 있을 것 같습니다.
우리 인간은 운전할 때 다른 자동차, 건물에 부딪히면 안된다는 걸 알고 있습니다.
이게 개념적, 추상적 인식이죠.
하지만 테슬라의 비전vision 머신러닝이 도로상황에서 확보한 수백만 대의 차량과 영상/이미지 데이터를 통해 구축된 자율주행 알고리듬에 이미지/영상 데이터에 비행기가 없었다면? ...
테슬라의 인공지능 비전은 처음 마주한 사물(의 일부분)이 무엇인지 판단하지 못하고 "비싼 비행기니깐 절대 부딪히면 안된다!" 라는 판단을 하지 못할 수 있는 거죠.
(이 사고 이후, 비행기 이미지들을 추가했길 바랍니다..)
이게 개리 마커스가 지적한 현 인공지능의 한계인 거 아닐까요?
이런 상황에서 시스템이 셀프-피드백과 평가를 할 수 있다고 해서 "더 나은 인공지능을 작성하는 인공지능"을 개발한다는 것이 가능하다고 추측할 수 있는 근거가 어디에 있을 지 궁금합니다.
대화형 인공지능과 대화를 통해 인류의 미래에 대한 이야기를 한다거나 '특이점'에 대해서 이야기를 한다고 한들, 지성이 아닌 패턴 생성을 하고 있는 알고리듬이 한 대사에 큰 의미를 부여할 필요가 없는 건 이 때문이라고 생각합니다.
인공지능이 인류를 말살시킬 방법을 얘기한다거나, 인류에 대한 증오를 표현한다거나 그런 대사들에는 의미가 있는 것이 아니라 알고리듬의 데이터 내에 있는 텍스트들을 재조합해서 질문과 관련된 텍스트를 생성해낸 것에 불과하다고 보는 게 제대로 된 해석인 것 같습니다.
우리가 "인공지능"이라고 부르면서 "인공"의 파트를 놓치면 공상과학적 상상에 휘말려 현실을 직시하지 못하게 되는 거죠.
오늘 오랜만에 다시 챗GPT에게 물어봤습니다. (영어로)
중국어 줄테니깐 한글로 번역해줘. 준비 됐니?
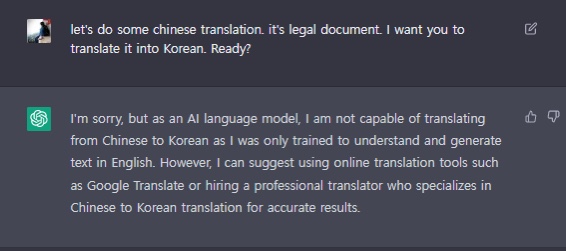
자긴 AI 언어 모델이라서 중국어를 한국어로 번역하는 능력이 없답니다. 자기는 영어 텍스트를 이해하고 생성하도록 훈련됐다며. 그러면서 정확한 결과를 위해 구글 번역이나 번역을 전문으로 하는 전문번역가를 쓸 것을 추천합니다.
챗GPT와의 첫 만남 때 이미 중국어로 대화를 해봤는데, 얘가 오늘은 왜 이럴까요.
무시하고 그냥 번역하라고 시키니깐 또 번역합니다.
인간이 인공지능을 인간으로 바라봤을 때는 "왜 거짓말을....!" 하며 느끼기 쉽지만, 제 명령에 챗GPT가 신중하게 대답하게 하는 키워드가 있었던 거라고 추측됩니다. Legal Document. 법률 문서라는 점에서 시스템 내의 파라미터의 무언가 존재하는 게 아닐까요.
개리 마커스가 지적한 많은 부분들을 챗GPT에게 직접 물어봤습니다.
이미 많은 것들에 대해 개리 마커스가 경험한 답변을 내놓지 않습니다. 파라미터를 추가한 거겠죠.
챗GPT는 법률조언, 정치적 비평, 종교적 평가 여러 가지 주제에 대해서 변호사 혹은 정치인 같은 답변을 할 때가 많습니다.
인공지능시대와 법적 책임
전 인공지능의 시대가 도입되는 것이 대중의 예상보다 순조롭지 않을 거라고 생각합니다. 개리 마커스가 얘기한 악용사례나 불완전한 기능을 제외하고도 또 다른 문제가 있습니다.
그건 바로 책임 입니다. 엄밀히 말하면 법적 책임이죠.
법과 관련된 업무를 하는 직장인으로서 인공지능의 한계란 것을 생각할 때 가장 먼저 떠오른 부분이 여기였습니다.
(1) 예를 들어 레벨-5 진정한 자율주행의 시대가 왔을 때, 인공지능이 운전하는 자율주행차량이 사고를 냈을 때, 개인도 법인도 아닌 '인공지능'이라고 불리는 알고리듬은 손해를 배상하는 책임의 주체가 누가 될 것인가?
어쩌면 이 질문을 차량제조사와 보험업계, 소비자협회가 아마 열심히 고민하고 있을 겁니다.
(2) 또 다른 사례는 "인간적 편견이 없는 인공지능에게 법관/재판관의 권한을 부여해서 공평한 판결을 하도록 하자!" 라는 주장을 생각해봅시다.
이론적으로는 피고와 원고 관련증거자료가 제출되고, 관련인들의 진술이 텍스트로 제공되고 제시되고 법 조항을 근거로 판결을 내는 거니깐 주관적 편견없이 "객관적인" 판결이 가능할 것처럼 생각할 수도 있겠습니다.
예상되는 문제점은
(1) 일단 현재의 인공지능 수준에선 텍스트에 대한 "이해력"이 부재하고, 이미지 분석으로 사물과 상황에 대한 이해를 할 수 있는 지식기반, 개념적 이해가 가능한 판단력이 없고
(2) 기계이기 때문에 객관적일 거라고 가정하는 건 안일한 생각일겁니다. 일단 데이터(선례/과거판례)에 기반한 결정을 한다면 결국 과거 판례의 성향에 따라 결정하는 것이기 때문에 독자적인 객관성이라기보단 과거의 가치관을 영속시키는 현상이 될 수 있겠죠.
또 데이터가 선별적이라고 하면 그 데이터를 선별한 인간의 주관이 개입될 수 밖에 없을 것이고, 그걸 랜덤화한다고 해서 객관성이 확보되는 건 아닙니다.
모든 데이터를 넣는 식으로 객관성을 확보할 수 있는 것 역시 아닙니다. 통계의 기반이 되는 데이터 안에 시대적 인식의 한계, 역사적 배경 속의 잘못된 판결이 있을 경우, 그게 영향을 미칠 것이고, 거기서 선별작업을 진행할 경우, 위에 말한 선별자의 주관이 개입되는 것이기 때문에 또 다시 객관성에 문제가 생깁니다.
(3) 판결이 잘못됐을 때의 책임 소재 역시 자율주행차량과 마찬가지의 문제를 마주하게 됩니다. 무고한 사람이 인공지능 재판의 오판으로 인해 옥살이를 한다거나, 사형을 당했다면?
*법이 사람 위에 있다는 개념의 출현은 인간사 속에서 자연스럽게 발생한 거라고 보기 어렵습니다. 단순히 프랑스혁명, 계몽주의, 민주주의의 출현으로 해석하면 더 깊은 역사적 배경을 면밀히 살펴보지 않고 의견을 내는 것일 수 있습니다.
그런데 그 법 위에 최종심판자, 판결 권한을 인공지능에게 맡긴다는 건 어떤 의미로는 '법의 신성함 (인간을 초월한다는 의미에서)'을 '인공지능의 신성함'으로 옮기는 것처럼 느껴질 수도 있겠네요.
또 내용이 너무 길어졌습니다.
전 아마 앞으로도 챗GPT에게 제가 할 수 있는 번역을 시키진 않을 겁니다. 머리는 자꾸 써야 좋아진다고 생각하기 때문이기도 하고, 인공지능에 대체되는 대세는 그런 걸 맡기면서 자기 능력계발에 소홀해 지는 추세에서 올거라고 생각해서 입니다.
어학공부 왜 해? 챗GPT, 구글번역, 파파고에 맡기면 되지ㅡ 라고 생각하시는 많은 분들껜 본질적인 질문 하나만 남기고 싶네요.
번역의 결과물의 품질, 정확도, 진위여부를 판단할 수 없다면 그건 무모한 도박이 아닐까요?
싱가포르 업체와의 계약서 번역 때 구글 번역을 활용해 본 적이 있습니다. 미세한 표현의 차이를 잘못 이해하고 조항의 반대 되는 해석을 한 적이 있었죠. 그게 틀렸다는 걸 알 수 있었던 건 제가 두 언어를 이해하기 때문이죠.
3부에선 AI에 대한 환상을 기반으로 존재하는 트랜스휴머니즘과 기독교에 대해 다뤄보고자 합니다.
긴 글 속에 조금이라도 쓸모있는 정보와 관점을 얻으셨길 바랍니다. 끝까지 읽어주셔서 감사합니다.
동영상의 시대인만큼 챗GPT에 대해 간략히 잘 설명해준 영상도 남깁니다